
Abstract
Text-guided diffusion models such as DALLE-2, Imagen, eDiff-I, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are of very high quality. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. The missing capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work, we take a particularly straightforward approach to providing the needed direction. Drawing on the observation that the cross-attention maps for prompt words reflect the spatial layout of objects denoted by those words, we introduce an optimization objective that produces ``activation'' at desired positions in these cross-attention maps. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. Directed Diffusion provides easy high-level positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
Update
Background
DD builds on the following observation: The overall position and shape of a synthesized objects appears near the beginning of the diffusion denoising process, while the final steps do not change this but keep refining the details.

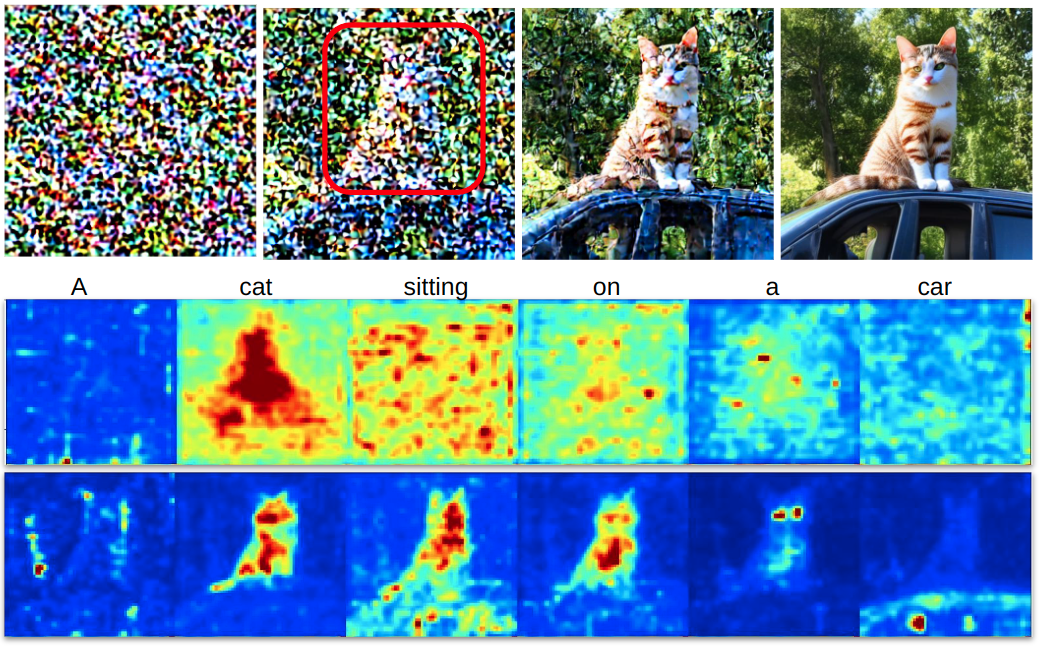
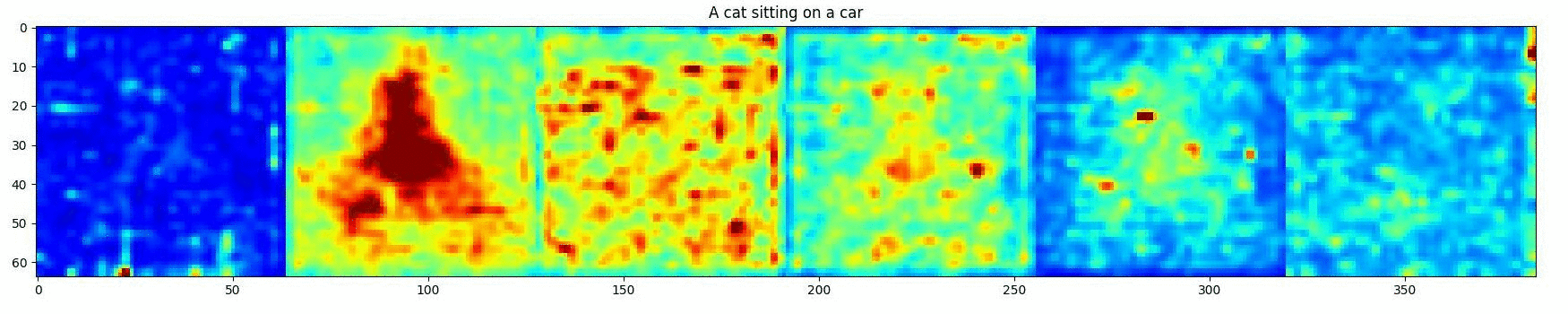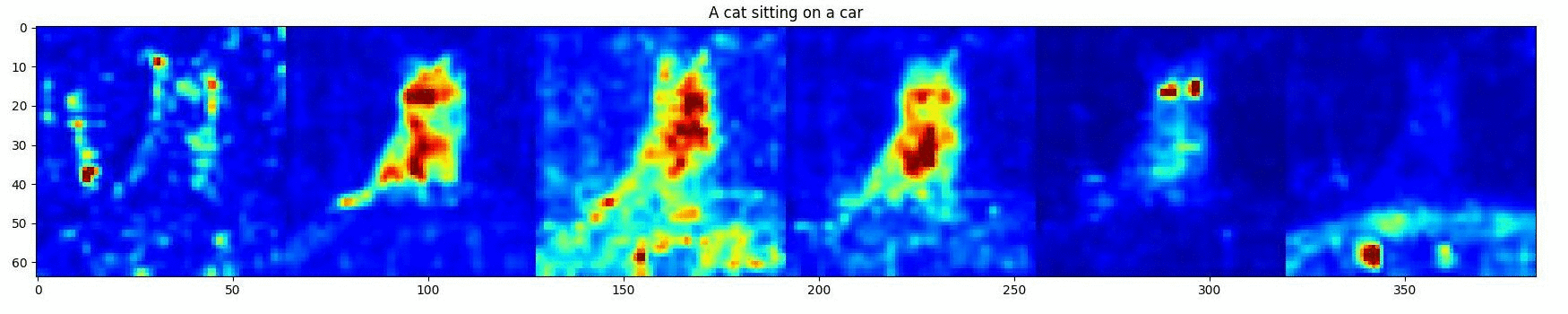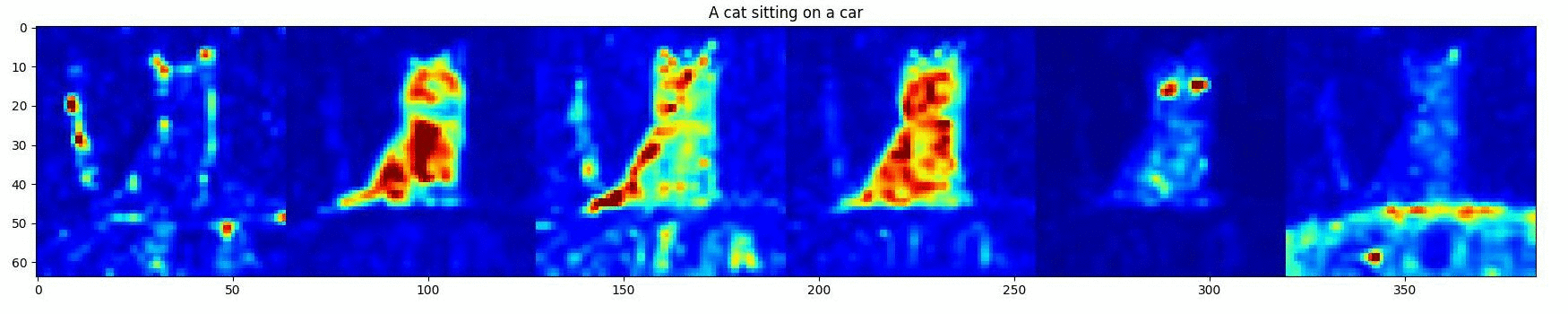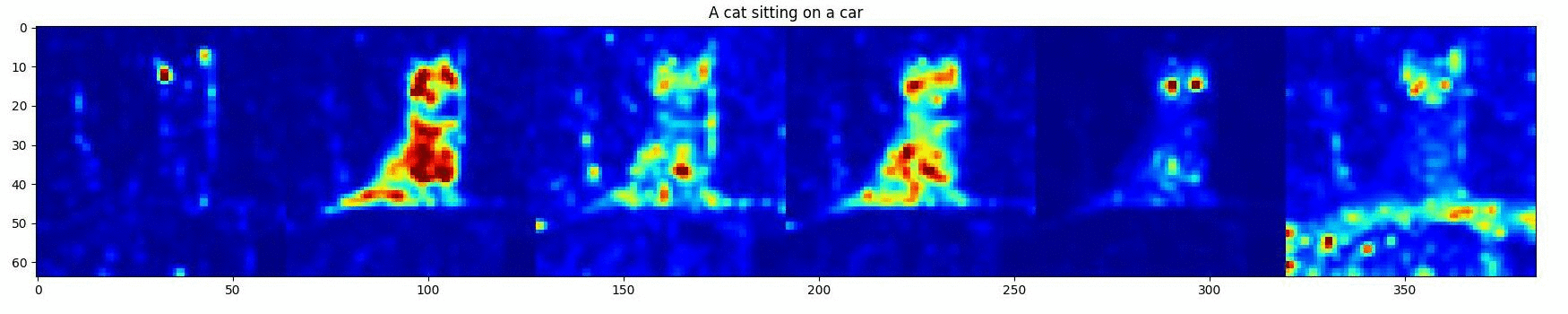
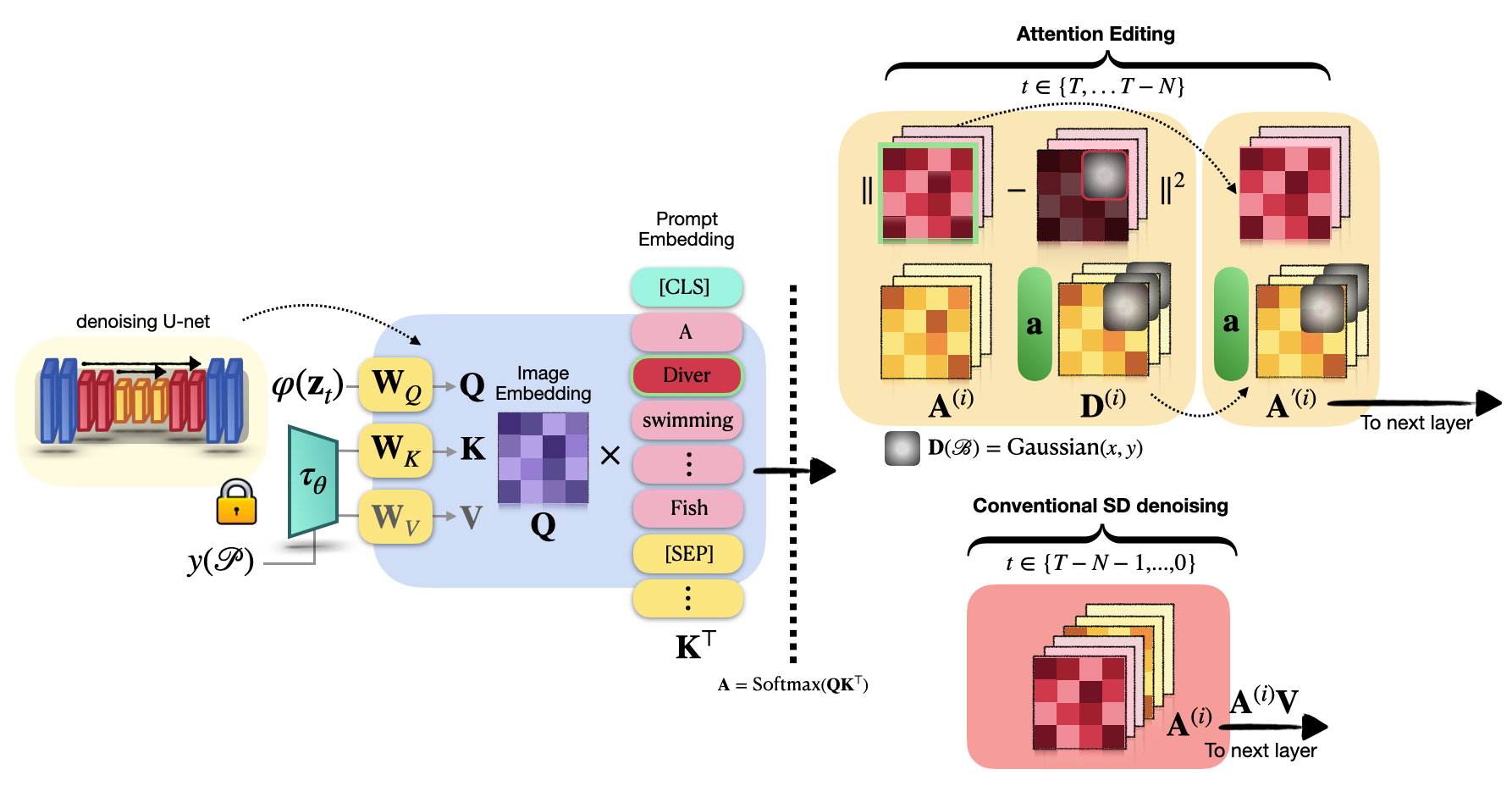
Approach
DD can be divided into two stages: Attention Editing and Convention SD Denoising . Our Attention Editing directly strengthens and weakens the activations in a specified region of selected cross-attention maps through optimization. Trailing attention maps are those that do not correspond to words in the prompt. These play a central role in establishing consistency between the subjects and the surrounding environment shown in the image. The optimal number of trailing attention maps are found by minimizing our objective that contributes the best directed object in the prompt attention maps.
Key Result - One object: Four quadrants
The following clip shows the directed object allocating in each of four image quadrants as well as at the image center, with the directed object a large cabin, an insect robot, and the sun, compared with conventional SD result shown at beginning.
Key Results - One object: Sliding window
The following clip shows the moving object from left to right. All the results are generated with a bounding box with the full image height and 40% of image width, with the directed object A stone castle, A white cat, A white dog, compared with conventional SD result shown at beginning.
Key Results - Placement Finetuning
In some cases the artist may wish to experiment with different object positions after obtaining a desirable image. However, when the object’s bounding box is moved DD may generate a somewhat different object. Our Placement Finetuning (PF) method addresses this problem, allowing the artist to immediately experiment with different positions for an object while keeping its identity, and without requiring any model fine-tuning or other optimization.
Key Results - Two bounding boxes
Compositionality is a well known failure case for SD, e.g. the Huggingface page specifically mentions the example of “A red cube on top of a blue sphere”. Here we use DD to successfully produce this example, by using two bounding boxes for the sphere and cube respectively.
Limitations
While Directed Diffusion can be used to address Stable Diffusion's problem with composing multiple objects, it inherits Stable Diffusion's other limitations -- in particular the need for experimentation with prompts and hyperparameters. "This is the thing with AI tools right now - it takes a ton of time and a willingness to keep experimenting." In practice our method would be used in conjunction with other algorithms such as Dreambooth. The examples in the paper do not make use of these other algorithms in order to provide a stand-alone evaluation of our algorithm.
Societal Impact
The aim of this project is to extend the capability of text-to-image models to visual storytelling. In common with most other technologies, there is potential for misuse. In particular, generative models reflect the biases of their training data, and there is a risk that malicious parties can use text-to-image methods to generate misleading images. The authors believe that it is important that these risks be addressed. This might be done by penalizing malicious behavior though the introduction of appropriate laws, or by limiting the capabilities of generative models to serve this behavior.
Contribution
- Storytelling : Our method is a first step towards storytelling by providing consistent control over the positioning of multiple objects.
- Compositionality : It provides an alternate and direct approach to ''compositionality'' by providing explicit positional control.
- Consistency : The positioned objects seamlessly and consistently fit in the environment, rather than appearing as a splice from another image with inconsistent interaction (shadows, lighting, etc.) This consistency is due to two factors.
- Simplicity : From a computational point of view, our method requires no training or fine tuning, and can be added to an existing text-driven diffusion model with cross-attention guidance with only a few lines of code. It requires a simple optimization of a small weight vector $\mathbf{a} ∈ \mathbb{R}^d$, $d < 77$, which does not significantly increase the overall synthesis time.
Acknowledgements
We thank Jason Baldridge, and the anonymous reviewers for helpful feedback. We also thank Huggingface public project Diffusers providing efficient and reliable experiments.
Citation
If you find our DirectedDiffusion interesting, please consider citing our article.
BibTeX
@misc{ma2023directed,
title={Directed Diffusion: Direct Control of Object Placement through Attention Guidance},
author={Wan-Duo Kurt Ma and J. P. Lewis and Avisek Lahiri and Thomas Leung and W. Bastiaan Kleijn},
year={2023},
eprint={2302.13153},
archivePrefix={arXiv},
primaryClass={cs.CV}
}